Trichter-Analyse SQL in der Warehouse-nativen Produktanalytik


Das Analysieren und Verstehen von Trichtern ist eine wichtige Fähigkeit für jeden Product Manager (PM). Sie hilft ihnen, die Nutzung von Produkten und Funktionen zu verstehen und zu optimieren, indem sie die Customer Journey von der Akquisition über die Aktivierung, Bindung, Weiterempfehlung und den Umsatz oder die Sub-Journeys der Benutzer durch jeden Workflow im Produkt verfolgen und visualisieren kann - und dabei Conversion Rate und Drop-off-Raten auf dem Weg dorthin aufzeigt. Mithilfe der Trichter-Analyse können PMs beliebige Erfolgskriterien definieren und die Schritte verfolgen, die ein Benutzer durchläuft, um die Erfolgskriterien im Falle einer Conversion zu erreichen, oder den Punkt im Produkt, an dem der Benutzer den Workflow abgebrochen hat, im Falle eines Abbruchs.
Diese Art der Analyse unterscheidet sich deutlich von der Business-Analyse, bei der Messwerte zu einer Reihe von dimensionalen Attributen aggregiert werden, um die Geschäftsergebnisse zu verstehen. Aufgrund meiner mehr als 10-jährigen Erfahrung in der Entwicklung von Hochleistungsdatenbanken bin ich jedoch der Meinung, dass moderne Data Warehouses gut gerüstet sind, um solche (eigentlich alle produktanalytischen) Workloads in großem Umfang effizient auszuführen.
In diesem Beitrag tauche ich tief in die Interna der Berechnungen ein, die hinter der Berechnung von Trichtern stehen, und beschreibe, wie moderne Data Warehouses Trichterabfragen in großem Maßstab ausführen können.
Was ist eine Trichteranalyse?
Wikipedia definiert die Trichteranalyse als die Abbildung und Analyse einer Reihe von Ereignissen, die zu einem bestimmten Ziel führen, wie z.B. der Weg von einer Anzeige zum Kauf in der Online-Werbung. Das folgende Beispiel zeigt die Conversion von Nutzern zur "Bezahlten Aktivierung" nach der Teilnahme an Schulungskursen auf einer Online-Lernplattform - 18,6 % der Nutzer nehmen nach "Erste Schritte" den "Analytics-Kurs" in Anspruch; und von diesen konvertieren 31 % der Nutzer zur "Bezahlten Aktivierung", was einer Gesamt-Conversion von 5,8 % entspricht.
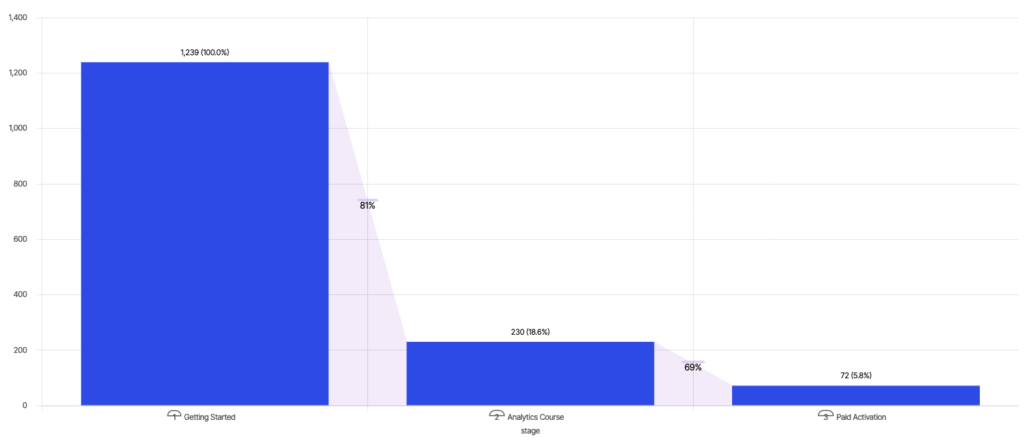
Ein PM, das sein Engagement erhöhen möchte, kann sich die Conversion Rate und die Abbruchraten zwischen den verschiedenen Phasen ansehen und beschließen, sich auf die Verbesserung der Conversion zwischen "Erste Schritte" und "Analytics-Kurs" zu konzentrieren, um die "Bezahlte Aktivierung" zu erhöhen.
Wie man einen Trichter aufbaut
Konzeptionell folgt ein Trichter einer geordneten Abfolge von Ereignissen nach "event_time" für jeden Benutzer, um die am weitesten entfernte Trichterstufe zu berechnen, die er erreicht hat. Es gibt mehrere Möglichkeiten, diese Berechnung mit SQL auszudrücken. Wir werden zwei solcher Muster behandeln und Ihnen einen Einblick in die Leistung beider geben. Doch bevor wir uns mit SQL befassen, sollten wir das für diese Analyse verwendete Datenmodell konkret definieren.
Datenmodell
Gehen wir von einem Schema mit einer einzigen Tabelle "Ereignisse" aus. Die Daten in "Ereignisse" können Sie sich wie folgt vorstellen:
| ereignis_name | ereignis_zeit | benutzer_id | OS | Browser |
| Erste Schritte | 0 | benutzer_id0 | ios | safari |
| Analytik-Kurs | 1 | benutzer_id0 |
ios |
safari |
| Analytik-Kurs | 1 | benutzer_id1 | android | chrom |
| Bezahlte Freischaltung | 4 | benutzer_id0 | ios | safari |
Ich habe in diesem Modell zwei vereinfachende Annahmen getroffen. Wie ich jedoch weiter unten erkläre, ist keine dieser Annahmen für moderne Data Warehouses von Belang.
- Strukturierte Daten - Es wird angenommen, dass "Ereignisse" eine strukturierte Tabelle sind, obwohl Ereignisdaten fast immer halbstrukturiert sind. Lesen Sie meinen vorherigen Blog, um zu verstehen, wie Data Warehouses mit halbstrukturierten Daten effizient umgehen.
- Keine Verknüpfungen - Tools der ersten Generation wie Amplitude und Mixpanel modellieren ihr Schema als einen einzigen Ereignisstrom. Dieses Modell kann sehr einschränkend sein, zumal für eine reale Analyse geschäftlicher Kontext aus anderen Quellen erforderlich ist. Im Gegensatz zu Produktanalysetools der ersten Generation wie Amplitude und Mixpanel, die nur sehr begrenzte Funktionen für Abfragen bieten, sind moderne Data Warehouses so konzipiert, dass sie mehrere Tabellen effizient miteinander verbinden können.
Trichter Abfrage

Abfrage-Engines analysieren und optimieren SQL-Text, um einen optimierten relationalen Plan für die Ausführung zu erstellen. Lassen Sie uns den optimierten relationalen Plan für diesen SQL-Text visualisieren, um sein Ausführungsprofil besser zu verstehen.Es gibt eine Unterabfrage für jede Stufe des Trichters:
- stage1 subquery gibt eindeutige user_ids aus, die auf das Ereignis "Getting Started" gestoßen sind
- stage2 subquery verknüpft die Tabelle "Events" mit der Ausgabe von stage1, um individuelle user_ids auszugeben, die nach dem Event "Getting Started" das Event "Analytics Course" erreicht haben
- Die Unterabfrage stage3 verknüpft die Tabelle "Events" mit der Ausgabe von stage2, um eindeutige user_ids auszugeben, die das Ereignis "Bezahlte Aktivierung" nach den Ereignissen "Erste Schritte" und "Analytics-Kurs" erreicht haben, und zwar in dieser Reihenfolge
- Die Ausgabe aller drei Stufen wird aggregiert, um die Anzahl der eindeutigen Benutzer in jeder Stufe zu zählen
Moderne Data Warehouses verfügen über extrem ausgefeilte Abfrageplaner zur Optimierung von relationalen Bäumen. Im obigen Plan gibt es zwei Optimierungen, die es wert sind, erwähnt zu werden:
- Der Optimierer berücksichtigt redundante Berechnungen im Plan als Teilpläne oder Fragmente, um die Ergebnisse in der gesamten Abfrage wiederzuverwenden. Die besten Engines planen Teilpläne adaptiv, um Ergebnisse und Statistiken für die weitere Planung zu verwenden.
- Die Aggregation in der "Endausgabe" wird unter die Verknüpfung geschoben - Optimierer der Spitzenklasse sollten in der Lage sein, daraus abzuleiten, dass die Aggregation bei Mehrfachverknüpfungen wie hier unter die linke Verknüpfung geschoben werden kann, um die Kosten für die teure linke Verknüpfung zwischen den drei Stufen zu vermeiden. Die Erstellung einer Abfrage, die vor der Verknüpfung aggregiert, ist auch eine praktikable Option für eine Analyse-Engine, falls der Optimierer nicht in der Lage ist, für dieses Muster zu optimieren.
Aggregier- und Join-Operationen sind das A und O für moderne Data Warehouses. Sie ermöglichen die effiziente Ausführung solcher Abfragen in großem Maßstab mit massiver Parallelität. Es gibt jedoch noch eine Reihe von Verbesserungen, die die Abfrageleistung weiter steigern können:
- Verknüpfungen zwischen Unterabfragen - Verknüpfungen zwischen Unterabfragen sind teurer als Verknüpfungen von Basistabellen, da bei Unterabfragen keine Verknüpfungsindizes vorberechnet werden. In unserem Beispiel werden "Ereignisse" und die Ausgaben der einzelnen Stufen auf Benutzerebene verbunden, was für Benutzer mit hoher Kardinalität kostspielig sein kann. Beachten Sie, dass der Cross-Join in der endgültigen Abfrage ziemlich billig ist, da er genau eine Zeile aus jeder Eingabe verbindet.
- Mehrfache Scans - Selbst nach der Entfernung redundanter Berechnungen wird die Tabelle "Events" dreimal gescannt, einmal für jede Unterabfrage. Ein schnellerer, effizienterer Algorithmus würde die Tabelle "Ereignisse" nur einmal durchsuchen.
Abfrage von gestapelten Fensterfunktionen
Ein alternativer Ansatz, um diese Berechnung zu deklarieren, ist die Verwendung von Fensterfunktionen. Fensterfunktionen ermöglichen eine zwingende Analyse im Stil einer Ereignisfolge über die deklarative SQL-Schnittstelle. Bei diesem Ansatz erstellen wir einen Stapel von Fensterfunktionen (partition over), eine für jede Stufe des Trichters, gefolgt von einer eindeutigen Zählung von "user_ids" an der Spitze dieses Stapels. Wir nennen dieses Muster "Stacked Window Functions". Hier ist die SQL-Abfrage zur Erstellung desselben Trichters mit Stacked Window Functions.

Die obige Abfrage ist zwar ausführlicher, erzeugt aber einen viel einfacheren relationalen Plan - der größte Teil der Komplexität für die Berechnung des Trichters wird in die Fensterfunktion verlagert.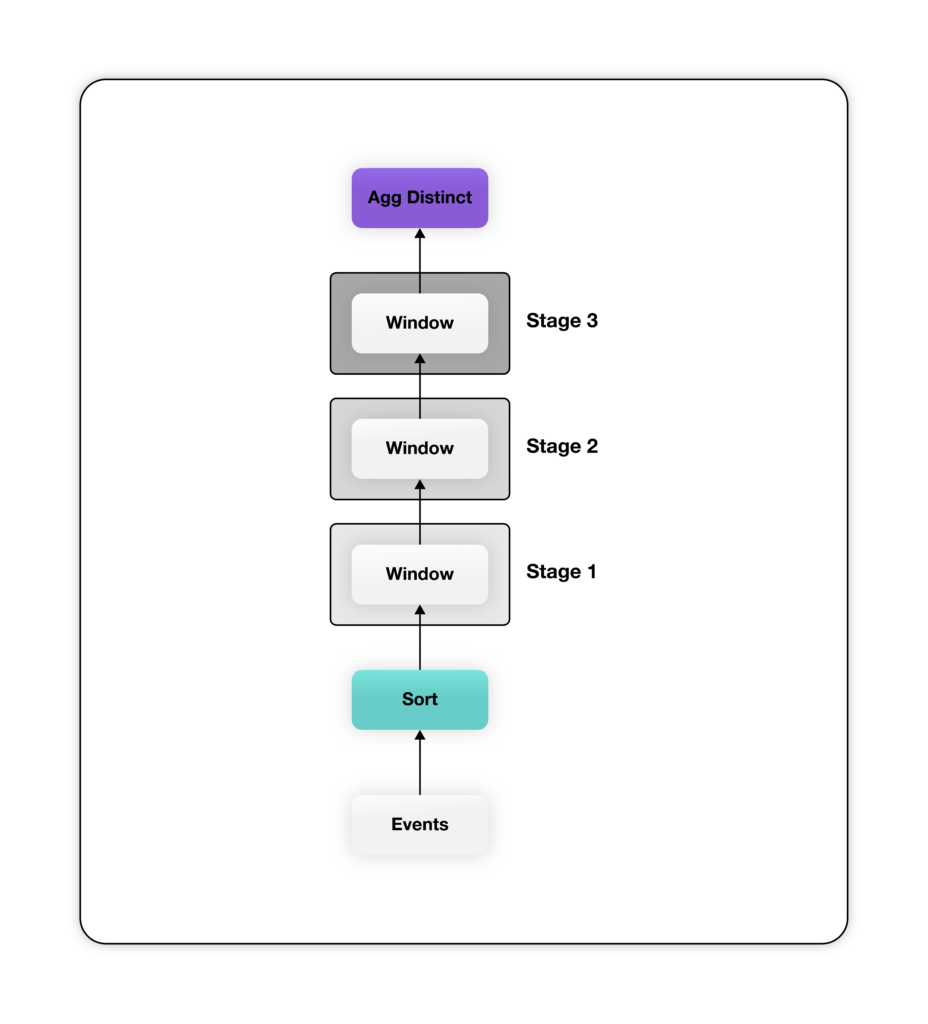 Der obige Plan hat eine Fensterfunktion für jede Stufe des Trichters. Beachten Sie, dass die im obigen SQL-Code definierten Window-Funktionen ihre Eingabe nach "user_id" aufteilen und nach "event_time" ordnen, um sicherzustellen, dass die Daten für jeden Benutzer von derselben Window-Funktionsinstanz in der aufsteigenden Reihenfolge der "event_time" verarbeitet werden. Jede Fensterfunktion gibt eine zusätzliche Spalte aus, die den frühesten Zeitstempel enthält, wenn der Benutzer die entsprechende Phase erreicht, oder null, wenn der Benutzer diese Phase nicht erreicht. Schließlich wird die Ausgabe des letzten Fensters, das eine Spalte mit "event_time" für jede Phase für alle Benutzer enthält, aggregiert, um die verschiedenen "user_ids" pro Phase zu zählen.
Der obige Plan hat eine Fensterfunktion für jede Stufe des Trichters. Beachten Sie, dass die im obigen SQL-Code definierten Window-Funktionen ihre Eingabe nach "user_id" aufteilen und nach "event_time" ordnen, um sicherzustellen, dass die Daten für jeden Benutzer von derselben Window-Funktionsinstanz in der aufsteigenden Reihenfolge der "event_time" verarbeitet werden. Jede Fensterfunktion gibt eine zusätzliche Spalte aus, die den frühesten Zeitstempel enthält, wenn der Benutzer die entsprechende Phase erreicht, oder null, wenn der Benutzer diese Phase nicht erreicht. Schließlich wird die Ausgabe des letzten Fensters, das eine Spalte mit "event_time" für jede Phase für alle Benutzer enthält, aggregiert, um die verschiedenen "user_ids" pro Phase zu zählen.
Wie zuvor nimmt der Abfrageplaner in den meisten modernen Data Warehouses zwei entscheidende Optimierungen vor, um die Leistung des obigen Plans zu verbessern:
- Einzelne Sortierung über alle Fenster - Alle Fensterfunktionen werden nach "user_id" partitioniert und nach "event_time" sortiert. In einem solchen Fall erstellt der Optimierer einen einzigen Sortieroperator, der die Daten in der gewünschten Reihenfolge an alle Fensterfunktionen weiterleitet.
- Lokale getrennte Aggregation - Die Abfrage hat eine getrennte Aggregation auf "user_id". Diese Aggregation kann innerhalb einer Partition (lokal) durchgeführt werden, wenn die Daten auf "user_id" vorpartitioniert sind, da die benutzerbasierte Partitionierung garantiert, dass die Benutzer nicht über Partitionen hinweg aggregiert werden müssen.
Die beiden oben aufgeführten Optimierungen sind in den meisten modernen Data Warehouses Standard. Diese Formulierung der Trichter-Abfrage hat keinen der Nachteile der Trichter-Abfrage im Stil der Join Sequence. Es gibt jedoch ein Problem, das behoben werden muss. Die Berechnung des Sortieroperators auf der Ereignisabfrage kann teuer erscheinen. Glücklicherweise muss diese Sortierung nicht global sein. Eine lokale Sortierung innerhalb der Partition ist ausreichend, da der Fensteroperator eine sortierte Eingabe pro Benutzer und nicht über alle Benutzer hinweg erfordert.
Es besteht die Möglichkeit, diese Abfrage noch weiter zu optimieren. Die meisten Data Warehouses bieten einen Knopf zum Clustern von Tabellen anhand eines vom Benutzer bereitgestellten Clustering Key. Der Clustering Key ist eine Reihe von Spalten oder Spaltenausdrücken, mit denen die Zeilen einer Tabelle zur Verbesserung der Leistung nahe beieinander angeordnet werden. Das Clustering der Tabelle "Ereignisse" nach "event_time" hat mehrere Vorteile:
- Reduzierung (oder sogar Eliminierung) der Kosten für den Sortieroperator, wenn die Daten fast (oder vollständig) nach Ereigniszeit sortiert sind
- Bessere Scan-Leistung bei Abfragen mit Zeitbereichsfiltern für die Spalte "event_time" bei "Events".
Fazit
In diesem Blog haben wir zwei verschiedene Formulierungen von Trichteranalyse-SQL vorgestellt und ihre jeweiligen Abfragepläne analysiert, um ihr Leistungsprofil in modernen Data Warehouses zu verstehen.
Tools der ersten Generation, wie Mixpanel und Amplitude, haben eine veraltete Architektur, die Datenbewegungen erfordert, Datensilos und Duplizierung schafft und zudem bei Skalierung unerschwinglich ist. Moderne Data Warehouses sind inzwischen so weit gereift, dass sie ein interaktives Erlebnis für Produktanalytik-Workloads ohne diese Unzulänglichkeiten und mit der Flexibilität von abstimmbaren Kosten für die gewünschte Leistung bieten können.
Optimizely Warehouse-Native Analytics kann sich mit allen wichtigen Cloud-Data-Warehouse-Anbietern verbinden, darunter Snowflake, BigQuery, Redshift und Databricks, um ein reichhaltiges Erlebnis für die Produktanalyse zu bieten - ohne jegliche Datenbewegung und zu einem Drittel der Kosten herkömmlicher Ansätze.
Über den Autor

