Vereinheitlichung der Produktanalytik im modernen Stack


Produktanalysetools wie Amplitude und Mixpanel gibt es schon seit über einem Jahrzehnt und sie sind älter als der moderne Datenstapel, der heute üblich ist. Es besteht nun eine Diskrepanz zwischen der Welt, für die diese Analysetools entwickelt wurden, und der Realität, wie Teams heute mit Unternehmensdaten arbeiten. Dies führt zu einer wichtigen Frage: Wie sollte sich die Produktanalytik weiterentwickeln, um in den modernen Datenstapel zu passen?
Um diese Frage zu beantworten, sollten wir uns zunächst eine grundlegende Frage stellen: Was ist der moderne Datenstapel?
Der moderne Datenstapel
In Bezug auf die Analytik definieren wir den modernen Datenstapel anhand der folgenden Merkmale:
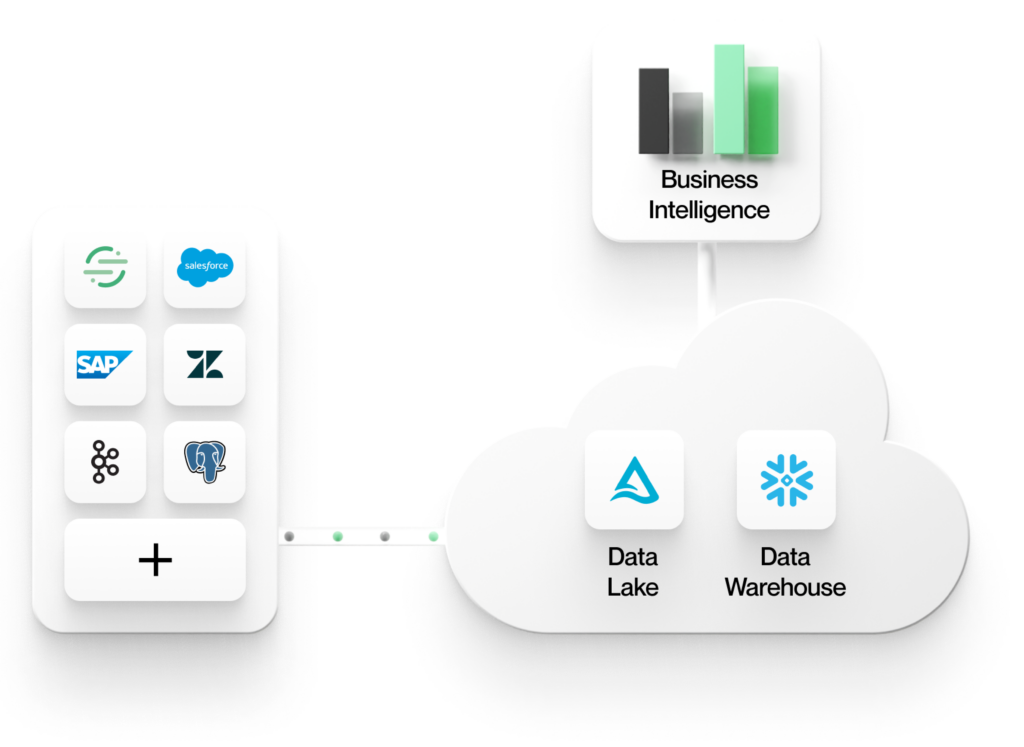
1. Alle Daten werden in einem gemeinsamen zentralen Unternehmensdatenspeicher in der Cloud gespeichert.
Dieser Speicher kann ein Data Lake sein, der auf einem Objektspeicher wie AWS S3 basiert, oder ein Data Warehouse wie Snowflake. Unabhängig davon, ob eine Lakehouse- oder Warehouse-Architektur verwendet wird, standardisieren Unternehmen alle Daten in zentralen Speichern. Ein gemeinsamer zentraler Speicher bietet Vorteile in Bezug auf Konsistenz, Sicherheit, Governance und Verwaltbarkeit.
2. Analysetools arbeiten direkt mit den Daten in diesen Speichern
Analysetools im modernen Data Stack, z.B. für Business Intelligence (BI) oder KI/ML, müssen die Daten nicht in andere Datensilos ETLen. Dies garantiert eine einzige Quelle der Wahrheit für Ihre Daten und liefert konsistente analytische Erkenntnisse für Ihr gesamtes Unternehmen. Durch die Verwendung offener Formate im Lake oder Warehouse werden Ihre Daten für jedes Tool zugänglich, so dass Sie sich nicht an einen Anbieter binden müssen. Die Arbeit direkt in einem zentralen Speicher macht es außerdem einfacher, aus Ihren Daten zu lernen und auf sie zu reagieren. Der gesamte Kontext, den Sie benötigen, befindet sich an einem Ort, anstatt über mehrere Silos verteilt zu sein.
Der Stand der Produktanalytik
Im Gegensatz zum zentralen Speicher moderner Datensysteme handelt es sich bei den meisten heute erhältlichen Produktanalysetools um isolierte, proprietäre, abgeschottete Systeme.
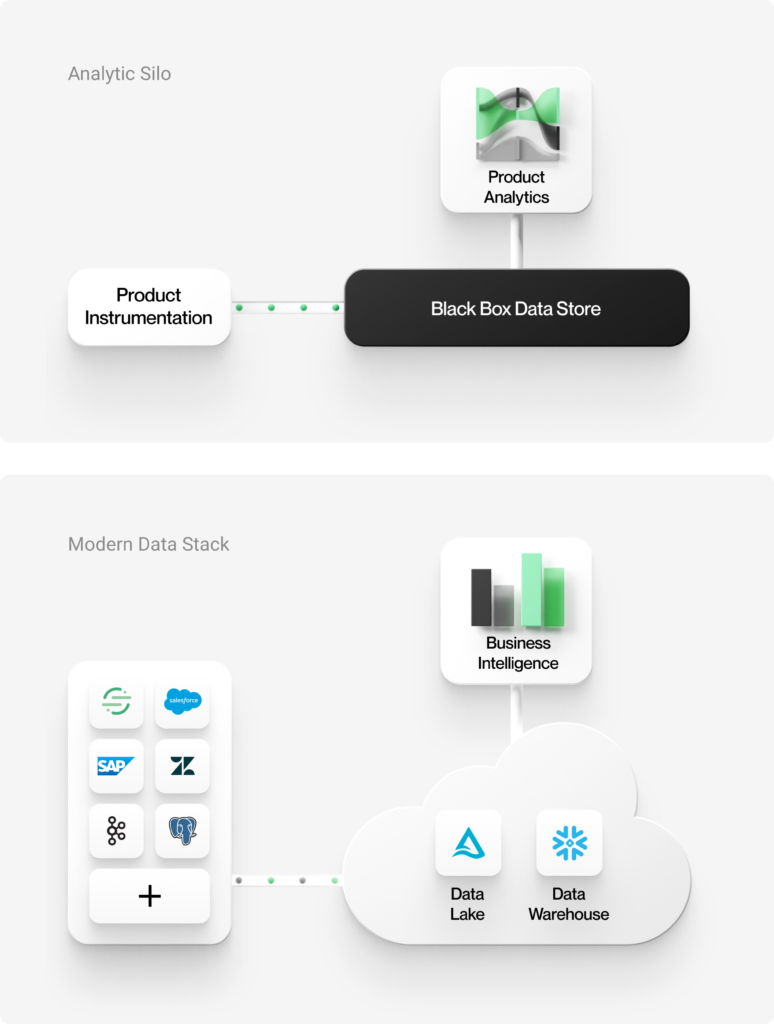
Isolierte Daten
In der Regel arbeiten Produktanalysetools mit isolierten Daten. Sie verfügen über integrierte Produktinstrumentierungsbibliotheken, die Daten in Blackbox-Speichern innerhalb einer geschlossenen Plattform sammeln und speichern. Selbst wenn Sie eine entkoppelte Instrumentenbibliothek eines Drittanbieters verwenden, müssen Ihre Daten in die Blackbox-Speicher des Tools übertragen werden, um ein Analysetool zu nutzen.
Da diese Produktanalysetools auf Silos beruhen, können sie nur mit einer Teilmenge Ihrer Daten arbeiten, die von der großen Mehrheit der Unternehmensdaten in Ihrem zentralen Speicher isoliert sind. Bestenfalls können Sie mit Hilfe von "Reverse ETL"-Tools einen kleinen Satz von Eigenschaften aus einem Data Warehouse oder Data Lake des Unternehmens einbringen. Leider handelt es sich dabei um einfache einwertige Eigenschaften, die in ein vorgefertigtes Datenmodell eingefügt werden müssen.
Aufgrund dieses isolierten Ansatzes ist es schwierig, die Erkenntnisse aus den Produktnutzungsdaten mit den Auswirkungen auf das gesamte Unternehmen zu verknüpfen. Diese Systeme können nur Ein-Kanal-Analysen durchführen, da ihnen der Kontext aus anderen Geschäftssystemen wie Vertrieb, Support, Voice of Customer und Finanzen fehlt.
Fragmentierte Analyse
Diese isolierte Architektur führt zu fragmentierten Analysen. Die Benutzer erhalten mit diesen traditionellen Produktanalysetools Analysen, die sich auf die Nutzung des Produkts beschränken. Wenn sie detailliertere Einblicke in das Kundenverhalten außerhalb des Produkts wünschen, müssen sie sich an ihre Data-Engineering- und BI-Teams wenden, um individuelle Berichte zu erstellen. Die Durchführung dieser Analyse kann Wochen dauern. Die Analysten müssen Daten aus den Blackbox-Speichern per ETL übertragen, komplexe SQL-Abfragen schreiben und BI-Tools anpassen, die nicht für diese Art von Analysen geeignet sind.
Das ist nicht nur komplex und kostspielig, sondern Sie haben jetzt auch Analysen in zwei getrennten Systemen, ohne die Möglichkeit, Kontext auszutauschen oder nahtlos zwischen ihnen hin- und herzuwechseln. Oft sind die Datenpipelines nicht miteinander verbunden, so dass die Analysten mit Snapshots (einmaligen benutzerdefinierten Berichten) arbeiten müssen. Das Vorhandensein mehrerer Datensilos stellt für Unternehmen ein massives TCO-Problem dar.
Außerdem gibt es Bedenken hinsichtlich der Sicherheit und des Datenschutzes. Es wird immer wichtiger, dass Kundendaten innerhalb der Grenzen der vom Unternehmen kontrollierten Speicher verbleiben und nicht in anderen, potenziell unsicheren und nicht konformen Umgebungen gespeichert werden.
Produktanalytik im modernen Datenstapel
Sehen wir uns nun an, wie die Produktanalyse aussehen sollte, wenn sie auf einem modernen Daten-Stack aufbaut.
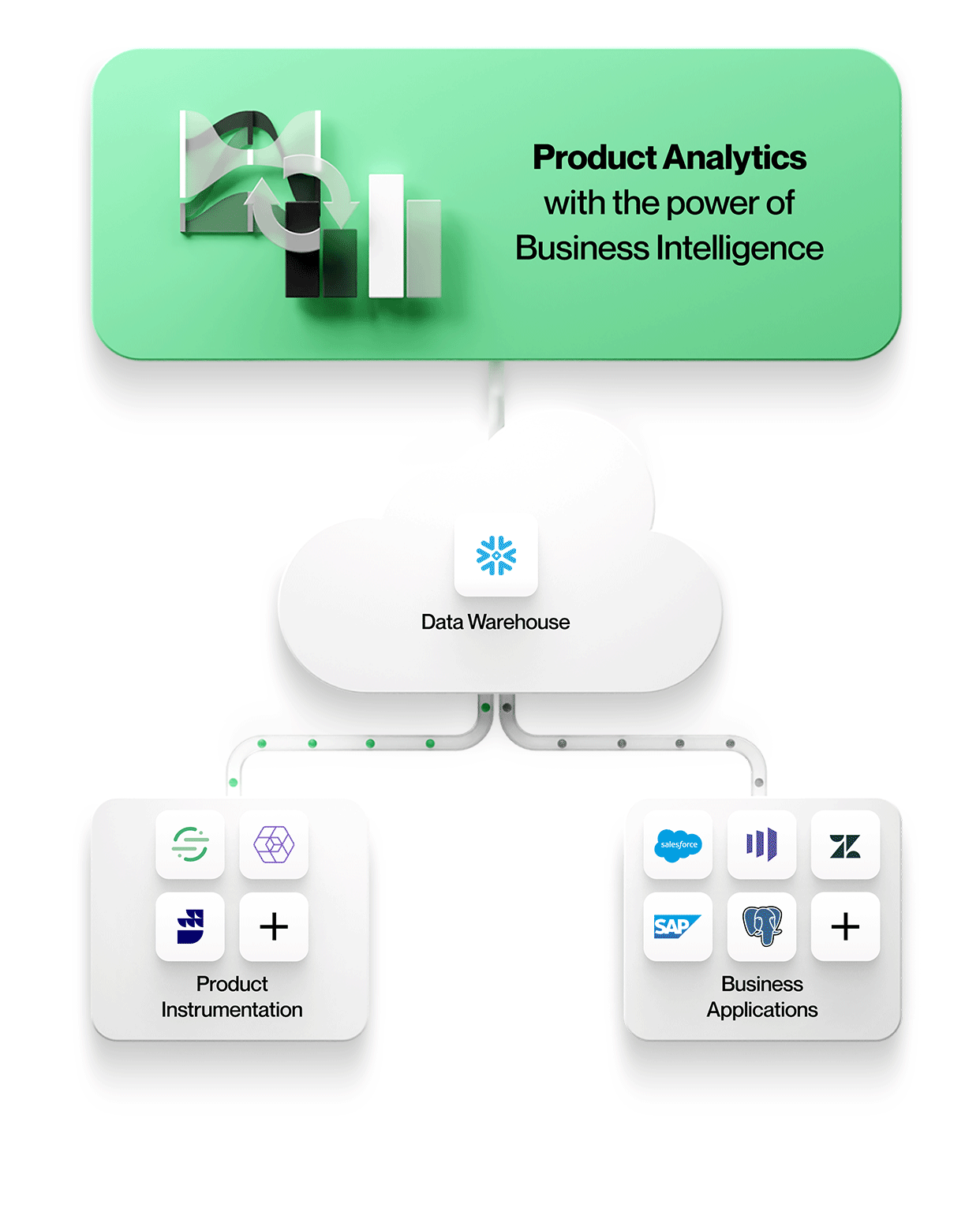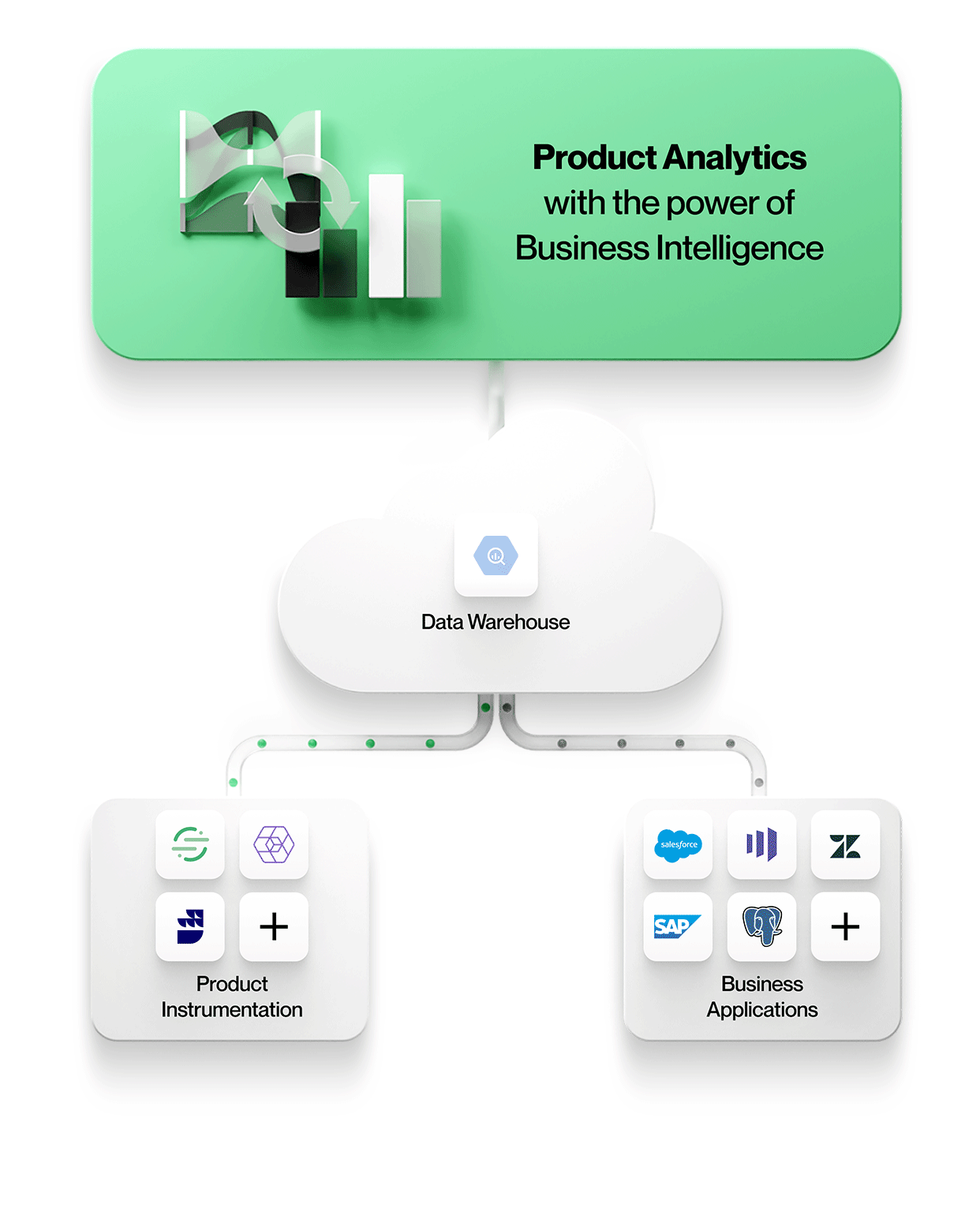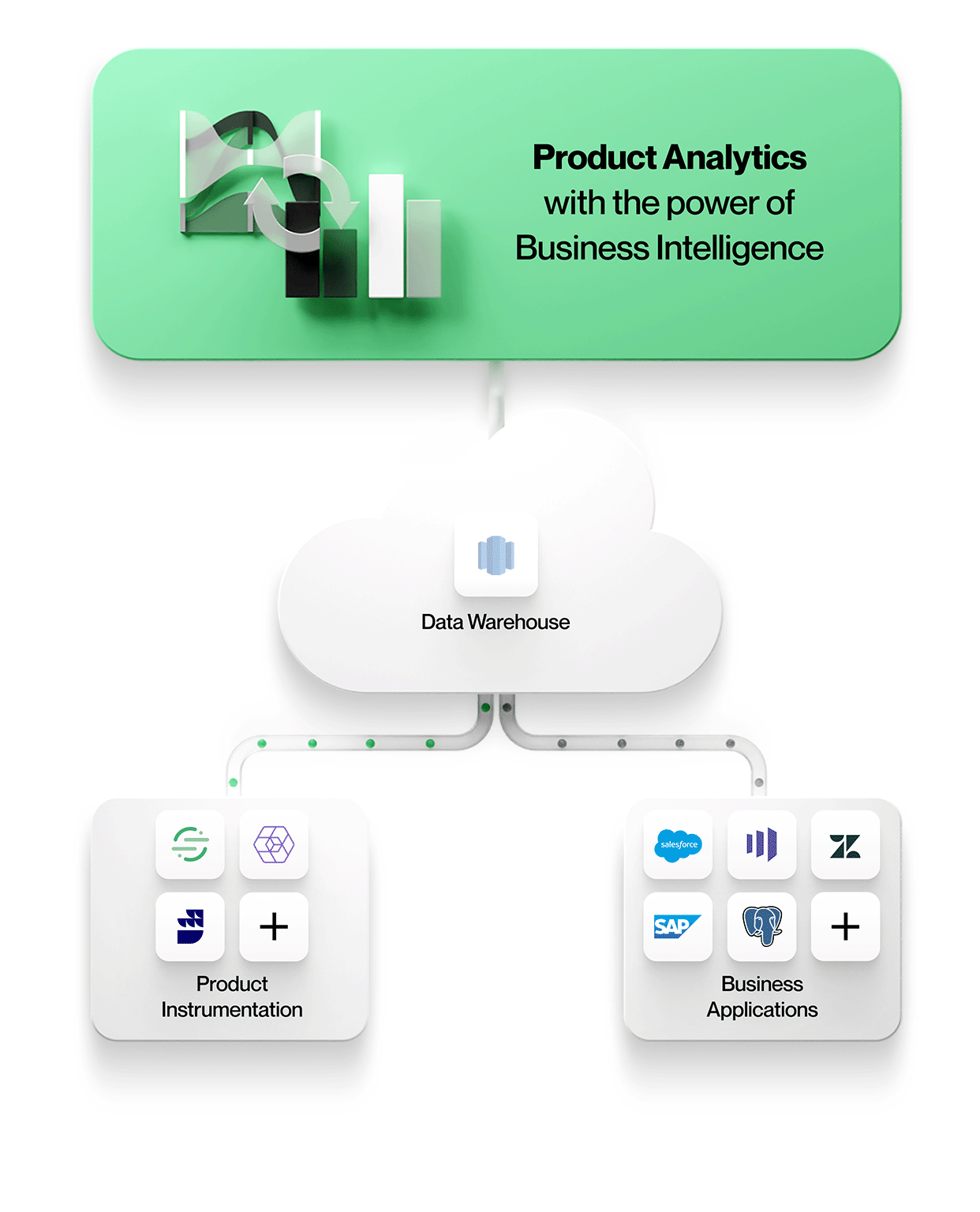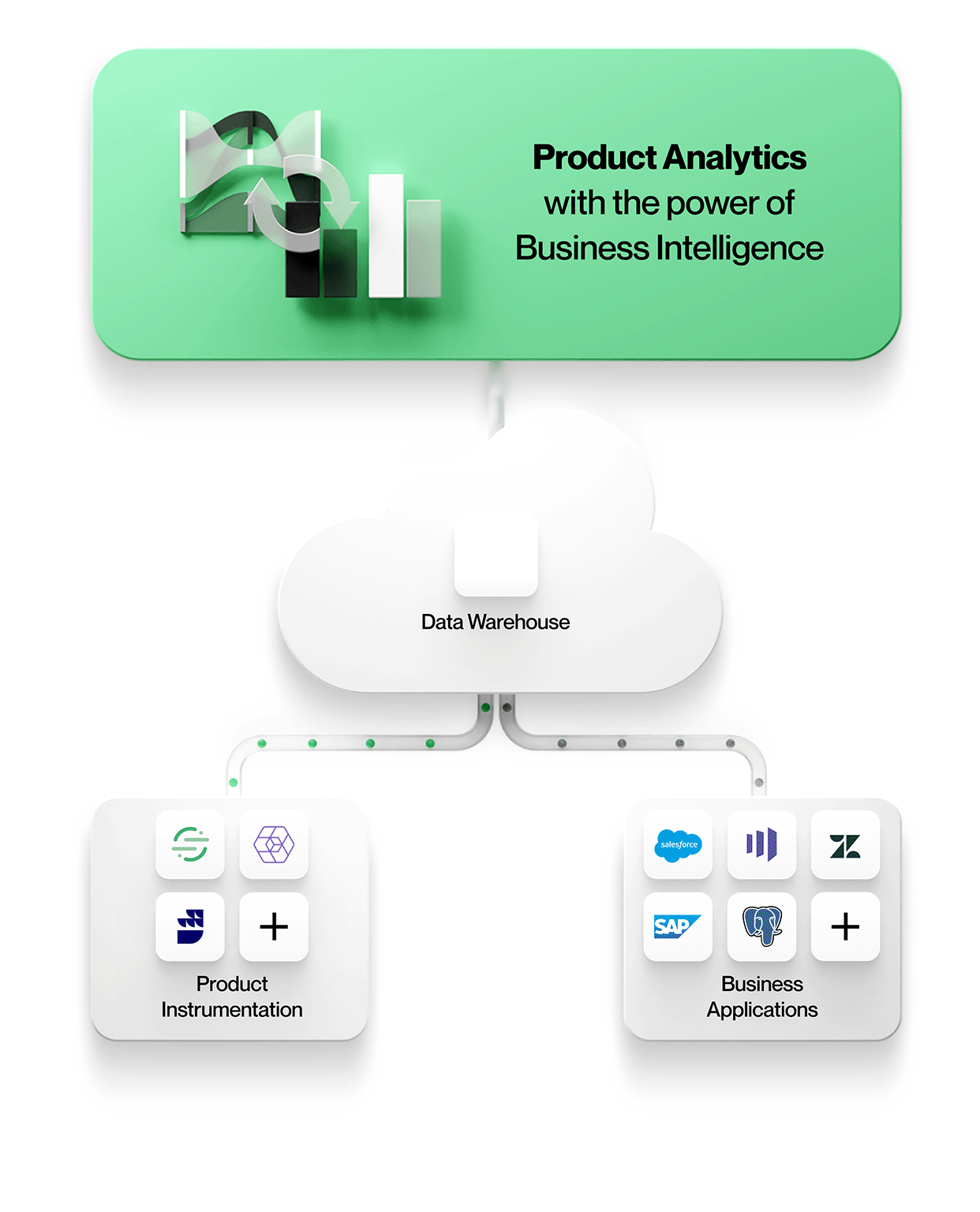
-
Produktinstrumentierungsdaten werden zusammen mit allen anderen Unternehmensdaten gespeichert
Alle Daten, einschließlich der Produktinstrumentierung, landen im selben zentralen Data Lake oder Warehouse. Dies vereinfacht die Verwaltung mit einem sicheren, verwalteten Speicher und vermeidet Datensilos. -
Die Produktinstrumentierung ist von der Analytik entkoppelt
Die Produktinstrumentierung ist frei von Rechthaberei. Sie schreibt kein bestimmtes Datenmodell vor und zwingt Sie auch nicht dazu, sich für ein bestimmtes Analysetool zu entscheiden.
Die entkoppelte und rezeptionsfreie Instrumentierung ermöglicht es Ihnen, Ihr einzigartiges Geschäft genau zu modellieren, anstatt Sie zu zwingen, ein vom Hersteller vorgegebenes Datenmodell zu verwenden. Außerdem können die instrumentierten Daten von jedem Analysetool verwendet werden. Produkte wie Snowplow und RudderStack ermöglichen eine solche entkoppelte Instrumentierung. -
Produktanalysetools arbeiten direkt mit den Daten im zentralen Data Lake oder im Enterprise Warehouse
Um kontextreiche Produktanalysen zu ermöglichen, beziehen Tools Daten aus anderen Geschäftssystemen in ihrer nativen Form mit ein. Das bedeutet, dass Sie mit Entitäten und ihren Beziehungen genau so arbeiten, wie sie in diesen Geschäftssystemen vorkommen, z.B. mit Entitäten wie Konten, Verträgen, Umsätzen und Leads aus Salesforce, Tickets, SLAs und Aufgaben aus Zendesk oder Kunden, Projekten und Tiers aus NetSuite. Produktanalysen können im Kontext verstanden und mit den Geschäftsergebnissen in Beziehung gesetzt werden, wodurch Ihre Analysen wertvoller und relevanter für jeden im Unternehmen werden.
Produktanalysedaten sollten genauso transformiert und abgefragt werden wie alle anderen Daten auch: z.B. mit DBT zur Datentransformation oder mit SQL zur Abfrage von Daten mit einem relationalen Modell. So können Sie das Know-how und die Tools nutzen, die in Ihrem Unternehmen bereits im Einsatz sind. Außerdem kann jedes beliebige Tool, z. B. ein KI/ML-Tool oder eine benutzerdefinierte Anwendung, diese Daten problemlos nutzen.
Insgesamt führt diese moderne Architektur für die Produktanalyse zu niedrigeren Gesamtbetriebskosten und einem höheren Geschäftsnutzen. Die Zukunft der Produktanalyse liegt darin, Ihre Daten in ihrem gesamten Kontext zu verstehen.
Möchten Sie Ihren Datenstapel um moderne Produktanalysen erweitern?
Optimizely Warehouse-Native Analytics bietet eine Produkt- und Verhaltensanalyseplattform der nächsten Generation, die speziell für den modernen Datenstapel entwickelt wurde.
Über den Autor

Entrepreneur, executive and product leader with a proven track record of conceiving and building innovative, successful, large-scale software systems Company builder...
