Analys av trattar SQL i warehouse-native product analytics


Att analysera och förstå trattar är en viktig färdighet för alla Product Managers (PM). Det hjälper dem att förstå och optimera användningen av produkter och funktioner genom att göra det möjligt för dem att spåra och visualisera kundresan från förvärv, genom aktivering, behålla kunder, hänvisning och intäkter; eller användarresor genom alla arbetsflöden i produkten - samtidigt som konverteringsoptimering och drop-off-frekvenser belyses längs vägen. Med hjälp av analys av trattar kan PM:s definiera framgångskriterier och spåra de steg en användare tar för att nå framgångskriterierna vid konvertering, eller den punkt i produkten där användaren avbröt arbetsflödet vid avhopp.
Den här typen av analys skiljer sig ganska mycket från affärsanalys, där man aggregerar åtgärder utifrån en uppsättning dimensionella attribut för att förstå affärsresultat. Men baserat på mina 10+ års erfarenhet av att bygga högpresterande databaser tror jag att moderna datalager är väl rustade för att effektivt utföra sådana (faktiskt alla produktanalyser) arbetsbelastningar i skala upp.
I det här inlägget kommer jag att dyka djupt in i de interna beräkningarna som ligger bakom beräkningen av trattar och beskriva hur moderna datalager kan utföra trattfrågor i skala upp.
Vad är analys av trattar?
Wikipedia definierar analys av trattar som kartläggning och analys av en serie händelser som leder till ett definierat mål, som en annons-till-köp-resa i onlineannonsering. Exemplet nedan följer konverteringen av användare till "Betald aktivering" efter att ha tagit utbildningskurser på en onlineplattform - 18,6 % av användarna tar "Analyskursen" efter "Komma igång"; och av dem konverterar 31 % av användarna till "Betald aktivering", vilket ger en total konvertering på 5,8 %.
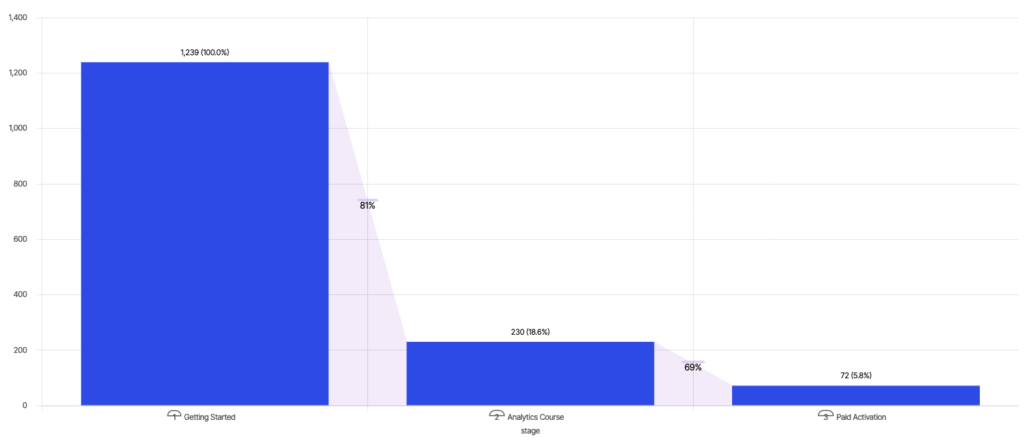
Ett PM som vill öka engagemanget kan titta på konverteringsgrad och drop-off mellan olika steg och besluta sig för att fokusera på att förbättra konverteringen mellan "Komma igång" och "Analyskurs" för att öka "Betald aktivering".
Hur man bygger en tratt
Konceptuellt följer en tratt en ordnad sekvens av händelser efter "event_time" för varje användare för att beräkna det längsta steget i tratten som de har nått. Det finns flera sätt att uttrycka denna beräkning med hjälp av SQL. Vi kommer att gå igenom två sådana mönster och ge insikter i prestandan för båda. Men innan vi hoppar till SQL ska vi konkret definiera den datamodell som används för denna analys.
Datamodell
Låt oss anta ett schema med en enda "Events"-tabell. Uppgifterna i "Events" kan tänkas ha följande form:
| händelsens_namn | event_time | user_id | OS | webbläsare |
| Komma igång | 0 | användare_id0 | ios | safari |
| Kurs i analys | 1 | användare_id0 |
ios |
safari |
| Analytisk kurs | 1 | användare_id1 | android | Chrome |
| Betald aktivering | 4 | användare_id0 | ios | safari |
Jag har gjort två förenklande antaganden i den här modellen, men som jag förklarar nedan är inget av dessa antaganden ett problemområde för moderna datalager.
- Strukturerade data - "Händelser" antas vara en strukturerad tabell även om händelsedata nästan alltid är semistrukturerade. Se min tidigare blogg för att förstå hur datalager hanterar halvstrukturerade data på ett effektivt sätt.
- No Joins - Första generationens verktyg som Amplitude och Mixpanel modellerar sitt schema som en enda händelseström. Den här modellen kan vara mycket begränsande, särskilt eftersom all analys i verkligheten kräver affärskontext från andra källor. Till skillnad från första generationens produktanalysverktyg som Amplitude och Mixpanel, som ger extremt begränsade frågefunktioner, är moderna datalager byggda för att effektivt ansluta flera tabeller.
Tratt-frågor

Frågemotorer analyserar och optimerar SQL-text för att skapa en optimerad relationell plan för körning. Låt oss visualisera den optimerade relationsplanen för denna SQL för att bättre förstå dess exekveringsprofil.Det finns en underfråga för varje steg i tratten:
- stage1-underfrågan skickar ut unika user_ids som stötte på "Komma igång"-händelsen
- steg2-underfrågan går med i tabellen "Händelser" med steg1-utdata för att ge ut enskilda user_ids som nådde händelsen "Analytics Course" efter händelsen "Getting Started"
- steg3-underfrågan deltar i tabellen "Händelser" med steg2-utdata för att ge ut unika user_ids som nådde händelsen "Betald aktivering" efter händelserna "Komma igång" och "Analyskurs", i den ordningen
- Utdata från alla tre stegen aggregeras för att räkna antalet unika användare i varje steg
Moderna datalager har extremt sofistikerade frågeplanerare för att optimera relationsträd. Det finns två optimeringar i planen ovan som är värda att ringa ut:
- Beräkning för varje steg sker en gång - Optimeraren räknar ut överflödigaberäkningar i planen som delplaner eller fragment för att återanvända resultat över hela frågan. De bästa motorerna i klassen schemalägger delplaner adaptivt för att använda resultat och statistik för vidare planering.
- Aggregering i "Final Output" skjuts under sammanfogningen - Optimiserare i bästa klass bör kunna dra slutsatsen att aggregering kan skjutas under vänster sammanfogning för många-till-en-sammanslagning, som här, för att eliminera kostnaden för dyr vänster sammanfogning mellan de tre stegen. Att skapa en fråga som aggregerar innan du går med är också ett genomförbart alternativ för en analysmotor om optimeraren inte kan optimera för detta mönster.
Aggregerade och delta i operationer är bröd och smör för moderna datalager, vilket gör att sådana frågor kan köras effektivt i skala upp med massiv parallellism. Det finns dock fortfarande ett par förbättringar som ytterligare kan förbättra frågornas prestanda:
- Sammanfogning mellanunderfrågor - Sammanfogningar mellan underfrågor är dyrare än sammanfogningar av bastabeller eftersom underfrågor inte har förberäknade sammanfogningsindex. I vårt exempel deltar "Händelser" och varje stegutgång vid användarkorn, vilket kan vara kostsamt för användare med hög kardinalitet. Observera att korsfogningen i den slutliga frågan är ganska billig eftersom den ansluter exakt en rad från varje ingång.
- Flera skanningar - Även efter att överflödiga beräkningar har tagits bort skannas tabellen "Events" tre gånger, en för varje underfråga. En snabbare och mer effektiv algoritm skulle bara skanna tabellen "Händelser" en gång.
Fråga om funktioner för staplade fönster
En alternativ metod för att förklara denna beräkning är att använda fönsterfunktioner. Fönsterfunktioner möjliggör imperativ analys i händelsesekvensstil via det deklarativa SQL-gränssnittet. I det här tillvägagångssättet skapar vi en stapel fönsterfunktioner (partition over), en för varje steg i tratten, följt av en räkning som skiljer sig från "user_ids" högst upp i denna stapel. Vi kallar det här mönstret för mönstret Stacked Window Functions. Här är SQL för att skapa samma tratt med hjälp av Stacked Window Functions.

Även om ovanstående fråga är mer mångordig skapar den en mycket enklare relationsplan - det mesta av komplexiteten för att beräkna tratten finns i fönsterfunktionen.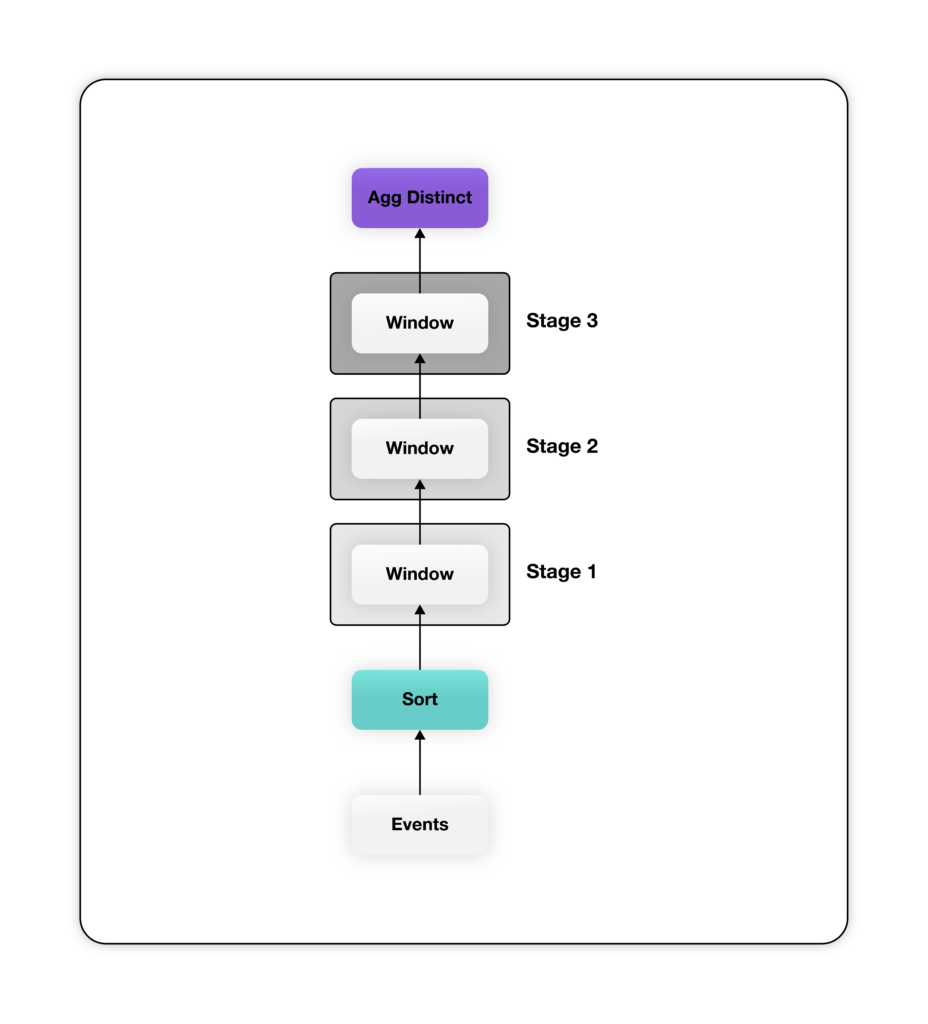 Planen ovan har en fönsterfunktion för varje steg i tratten. Observera att de fönsterfunktioner som definieras i SQL-koden ovan delar upp sin indata efter "user_id" och beställer efter "event_time" för att säkerställa att data för varje användare behandlas av samma fönsterfunktionsinstans i stigande ordning efter "event_time". Varje window-funktion skickar ut en extra kolumn som innehåller den tidigaste tidsstämpeln när användaren når motsvarande steg, eller null om användaren inte når det steget. Slutligen aggregeras utdata från det sista fönstret, som innehåller en kolumn med "event_time" för varje steg för alla användare, för att räkna distinkta "user_ids" per steg.
Planen ovan har en fönsterfunktion för varje steg i tratten. Observera att de fönsterfunktioner som definieras i SQL-koden ovan delar upp sin indata efter "user_id" och beställer efter "event_time" för att säkerställa att data för varje användare behandlas av samma fönsterfunktionsinstans i stigande ordning efter "event_time". Varje window-funktion skickar ut en extra kolumn som innehåller den tidigaste tidsstämpeln när användaren når motsvarande steg, eller null om användaren inte når det steget. Slutligen aggregeras utdata från det sista fönstret, som innehåller en kolumn med "event_time" för varje steg för alla användare, för att räkna distinkta "user_ids" per steg.
Precis som tidigare gör frågeplaneraren i de flesta moderna datalager två kritiska optimeringar för att förbättra prestandan för ovanstående plan:
- Single Sort across Windows - Alla fönsterfunktioner är partitionerade på "user_id" och sorterade på "event_time". I ett sådant fall skapar optimeraren en enda sorteringsoperatör som matar data i önskad ordning till alla fönsterfunktioner.
- Lokal distinkt aggregering - Frågan har en distinkt aggregering på "user_id". Denna aggregering kan utföras inom en partition (lokalt) om data är förpartitionerade på "user_id" eftersom användarbaserad partitionering garanterar att användare inte behöver aggregeras över partitioner.
Båda de optimeringar som anges ovan är standard i de flesta moderna datalager. Denna formulering av tratt-frågan har inte någon av bristerna i Join Sequence-stilen av tratt-frågan. Det finns dock ett problem som måste åtgärdas. Sorteringsoperatorn ovanpå händelsesökningen kan verka dyr att beräkna. Lyckligtvis behöver denna sortering inte vara global; det räcker med att sortera lokalt inom partitionen eftersom fönsteroperatorn kräver sorterad indata per användare och inte mellan användare.
Det finns potential att optimera den här frågan ytterligare. De flesta datalager erbjuder en knopp för att klustra tabeller med hjälp av en användartillhandahållen klustringsnyckel. Clustering Key är en uppsättning kolumner eller kolumnuttryck som används för att placera rader i en tabell nära varandra för förbättrad prestanda. Klustring av tabellen "Events" efter "event_time" har flera fördelar:
- Minska (kanske till och med eliminera) kostnaden för Sort-operatorn om data nästan (eller helt) är sorterade efter händelsetid
- Förbättra skanningsprestanda på "Events" för frågor med tidsintervallfilter på kolumnen "event_time"
Slutsats
I den här bloggen presenterade vi två olika formuleringar av SQL för analys av trattar och analyserade deras respektive frågeplaner för att förstå deras prestandaprofil i moderna datalager.
Första generationens verktyg, som Mixpanel och Amplitude, har en föråldrad arkitektur som kräver dataförflyttning, skapar åtskilda data och duplicering, och är dessutom oöverkomligt dyra i skala upp. Moderna datalager har mognat till en punkt där de kan ge en interaktiv upplevelse för produktanalys utan dessa brister och flexibiliteten med inställbar kostnad för önskvärd prestanda.
Optimizely Warehouse-native Analytics kan ansluta till alla större datalagerleverantörer i molnet, inklusive Snowflake, BigQuery, Redshift och Databricks för att ge en rik produktanalysupplevelse - utan dataförflyttning och till en tredjedel av kostnaden för äldre metoder.
Om författaren

